Master Appian ACD301 Exam with Reliable Practice Questions
Your team has deployed an application to Production with an underperforming view. Unexpectedly, the production data is ten times that of what was tested, and you must remediate the issue. What is the best option you can take to mitigate their performance concerns?
Correct : C
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, addressing performance issues in production requires balancing Appian's best practices, scalability, and maintainability. The scenario involves an underperforming view due to a significant increase in data volume (ten times the tested amount), necessitating a solution that optimizes performance while adhering to Appian's architecture. Let's evaluate each option:
A . Bypass Appian's query rule by calling the database directly with a SQL statement:
This approach involves circumventing Appian's query rules (e.g., a!queryEntity) and directly executing SQL against the database. While this might offer a quick performance boost by avoiding Appian's abstraction layer, it violates Appian's core design principles. Appian Lead Developer documentation explicitly discourages direct database calls, as they bypass security (e.g., Appian's row-level security), auditing, and portability features. This introduces maintenance risks, dependencies on database-specific logic, and potential production instability---making it an unsustainable and non-recommended solution.
B . Create a table which is loaded every hour with the latest data:
This suggests implementing a staging table updated hourly (e.g., via an Appian process model or ETL process). While this could reduce query load by pre-aggregating data, it introduces latency (data is only fresh hourly), which may not meet real-time requirements typical in Appian applications (e.g., a customer-facing view). Additionally, maintaining an hourly refresh process adds complexity and overhead (e.g., scheduling, monitoring). Appian's documentation favors more efficient, real-time solutions over periodic refreshes unless explicitly required, making this less optimal for immediate performance remediation.
C . Create a materialized view or table:
This is the best choice. A materialized view (or table, depending on the database) pre-computes and stores query results, significantly improving retrieval performance for large datasets. In Appian, you can integrate a materialized view with a Data Store Entity, allowing a!queryEntity to fetch data efficiently without changing application logic. Appian Lead Developer training emphasizes leveraging database optimizations like materialized views to handle large data volumes, as they reduce query execution time while keeping data consistent with the source (via periodic or triggered refreshes, depending on the database). This aligns with Appian's performance optimization guidelines and addresses the tenfold data increase effectively.
D . Introduce a data management policy to reduce the volume of data:
This involves archiving or purging data to shrink the dataset (e.g., moving old records to an archive table). While a long-term data management policy is a good practice (and supported by Appian's Data Fabric principles), it doesn't immediately remediate the performance issue. Reducing data volume requires business approval, policy design, and implementation---delaying resolution. Appian documentation recommends combining such strategies with technical fixes (like C), but as a standalone solution, it's insufficient for urgent production concerns.
Conclusion: Creating a materialized view or table (C) is the best option. It directly mitigates performance by optimizing data retrieval, integrates seamlessly with Appian's Data Store, and scales for large datasets---all while adhering to Appian's recommended practices. The view can be refreshed as needed (e.g., via database triggers or schedules), balancing performance and data freshness. This approach requires collaboration with a DBA to implement but ensures a robust, Appian-supported solution.
Appian Documentation: 'Performance Best Practices' (Optimizing Data Queries with Materialized Views).
Appian Lead Developer Certification: Application Performance Module (Database Optimization Techniques).
Appian Best Practices: 'Working with Large Data Volumes in Appian' (Data Store and Query Performance).
Start a Discussions
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage
Review the specs for four environments in the following image.
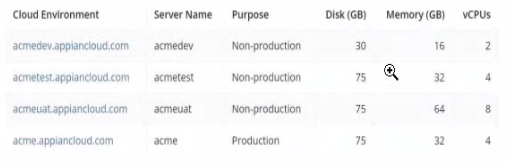
Which environment should you use for load testing7
Correct : A
The image provides the specifications for four environments in the Appian Cloud:
acmedev.appiancloud.com (acmedev): Non-production, Disk: 30 GB, Memory: 16 GB, vCPUs: 2
acmetest.appiancloud.com (acmetest): Non-production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4
acmeuat.appiancloud.com (acmeuat): Non-production, Disk: 75 GB, Memory: 64 GB, vCPUs: 8
acme.appiancloud.com (acme): Production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4
Load testing assesses an application's performance under increased user load to ensure scalability and stability. Appian's Performance Testing Guidelines emphasize using an environment that mirrors Production as closely as possible to obtain accurate results, while avoiding direct impact on live systems.
Option A (acmeuat): This is the best choice. The UAT (User Acceptance Testing) environment (acmeuat) has the highest resources (64 GB memory, 8 vCPUs) among the non-production environments, closely aligning with Production's capabilities (32 GB memory, 4 vCPUs) but with greater capacity to handle simulated loads. UAT environments are designed to validate the application with real-world usage scenarios, making them ideal for load testing. The higher resources also allow testing beyond current Production limits to predict future scalability, meeting the client's goal of increasing active users without risking live data.
Option B (acmedev): The development environment (acmedev) has the lowest resources (16 GB memory, 2 vCPUs), which is insufficient for load testing. It's optimized for development, not performance simulation, and results would not reflect Production behavior accurately.
Option C (acme): The Production environment (acme) is live with users, and load testing here would disrupt service, violate Appian's Production Safety Guidelines, and risk data integrity. It should never be used for testing.
Option D (acmetest): The test environment (acmetest) has moderate resources (32 GB memory, 4 vCPUs), matching Production's memory and vCPUs. However, it's typically used for SIT (System Integration Testing) and has less capacity than acmeuat. While viable, it's less ideal than acmeuat for simulating higher user loads due to its resource constraints.
Appian recommends using a UAT environment for load testing when it closely mirrors Production and can handle simulated traffic, making acmeuat the optimal choice given its superior resources and non-production status.
Start a Discussions
You need to connect Appian with LinkedIn to retrieve personal information about the users in your application. This information is considered private, and users should allow Appian to retrieve their information. Which authentication method would you recommend to fulfill this request?
Correct : D
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, integrating with an external system like LinkedIn to retrieve private user information requires a secure, user-consented authentication method that aligns with Appian's capabilities and industry standards. The requirement specifies that users must explicitly allow Appian to access their private data, which rules out methods that don't involve user authorization. Let's evaluate each option based on Appian's official documentation and LinkedIn's API requirements:
A . API Key Authentication:
API Key Authentication involves using a single static key to authenticate requests. While Appian supports this method via Connected Systems (e.g., HTTP Connected System with an API key header), it's unsuitable here. API keys authenticate the application, not the user, and don't provide a mechanism for individual user consent. LinkedIn's API for private data (e.g., profile information) requires per-user authorization, which API keys cannot facilitate. Appian documentation notes that API keys are best for server-to-server communication without user context, making this option inadequate for the requirement.
B . Basic Authentication with user's login information:
This method uses a username and password (typically base64-encoded) provided by each user. In Appian, Basic Authentication is supported in Connected Systems, but applying it here would require users to input their LinkedIn credentials directly into Appian. This is insecure, impractical, and against LinkedIn's security policies, as it exposes user passwords to the application. Appian Lead Developer best practices discourage storing or handling user credentials directly due to security risks (e.g., credential leakage) and maintenance challenges. Moreover, LinkedIn's API doesn't support Basic Authentication for user-specific data access---it requires OAuth 2.0. This option is not viable.
C . Basic Authentication with dedicated account's login information:
This involves using a single, dedicated LinkedIn account's credentials to authenticate all requests. While technically feasible in Appian's Connected System (using Basic Authentication), it fails to meet the requirement that ''users should allow Appian to retrieve their information.'' A dedicated account would access data on behalf of all users without their individual consent, violating privacy principles and LinkedIn's API terms. LinkedIn restricts such approaches, requiring user-specific authorization for private data. Appian documentation advises against blanket credentials for user-specific integrations, making this option inappropriate.
D . OAuth 2.0: Authorization Code Grant:
This is the recommended choice. OAuth 2.0 Authorization Code Grant, supported natively in Appian's Connected System framework, is designed for scenarios where users must authorize an application (Appian) to access their private data on a third-party service (LinkedIn). In this flow, Appian redirects users to LinkedIn's authorization page, where they grant permission. Upon approval, LinkedIn returns an authorization code, which Appian exchanges for an access token via the Token Request Endpoint. This token enables Appian to retrieve private user data (e.g., profile details) securely and per user. Appian's documentation explicitly recommends this method for integrations requiring user consent, such as LinkedIn, and provides tools like a!authorizationLink() to handle authorization failures gracefully. LinkedIn's API (e.g., v2 API) mandates OAuth 2.0 for personal data access, aligning perfectly with this approach.
Conclusion: OAuth 2.0: Authorization Code Grant (D) is the best method. It ensures user consent, complies with LinkedIn's API requirements, and leverages Appian's secure integration capabilities. In practice, you'd configure a Connected System in Appian with LinkedIn's Client ID, Client Secret, Authorization Endpoint (e.g., https://www.linkedin.com/oauth/v2/authorization), and Token Request Endpoint (e.g., https://www.linkedin.com/oauth/v2/accessToken), then use an Integration object to call LinkedIn APIs with the access token. This solution is scalable, secure, and aligns with Appian Lead Developer certification standards for third-party integrations.
Appian Documentation: 'Setting Up a Connected System with the OAuth 2.0 Authorization Code Grant' (Connected Systems).
Appian Lead Developer Certification: Integration Module (OAuth 2.0 Configuration and Best Practices).
LinkedIn Developer Documentation: 'OAuth 2.0 Authorization Code Flow' (API Authentication Requirements).
Start a Discussions
A customer wants to integrate a CSV file once a day into their Appian application, sent every night at 1:00 AM. The file contains hundreds of thousands of items to be used daily by users as soon as their workday starts at 8:00 AM. Considering the high volume of data to manipulate and the nature of the operation, what is the best technical option to process the requirement?
Correct : C
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, handling a daily CSV integration with hundreds of thousands of items requires a solution that balances performance, scalability, and Appian's architectural strengths. The timing (1:00 AM integration, 8:00 AM availability) and data volume necessitate efficient processing and minimal runtime overhead. Let's evaluate each option based on Appian's official documentation and best practices:
A . Use an Appian Process Model, initiated after every integration, to loop on each item and update it to the business requirements:
This approach involves parsing the CSV in a process model and using a looping mechanism (e.g., a subprocess or script task with fn!forEach) to process each item. While Appian process models are excellent for orchestrating workflows, they are not optimized for high-volume data processing. Looping over hundreds of thousands of records would strain the process engine, leading to timeouts, memory issues, or slow execution---potentially missing the 8:00 AM deadline. Appian's documentation warns against using process models for bulk data operations, recommending database-level processing instead. This is not a viable solution.
B . Build a complex and optimized view (relevant indices, efficient joins, etc.), and use it every time a user needs to use the data:
This suggests loading the CSV into a table and creating an optimized database view (e.g., with indices and joins) for user queries via a!queryEntity. While this improves read performance for users at 8:00 AM, it doesn't address the integration process itself. The question focuses on processing the CSV (''manipulate'' and ''operation''), not just querying. Building a view assumes the data is already loaded and transformed, leaving the heavy lifting of integration unaddressed. This option is incomplete and misaligned with the requirement's focus on processing efficiency.
C . Create a set of stored procedures to handle the volume and the complexity of the expectations, and call it after each integration:
This is the best choice. Stored procedures, executed in the database, are designed for high-volume data manipulation (e.g., parsing CSV, transforming data, and applying business logic). In this scenario, you can configure an Appian process model to trigger at 1:00 AM (using a timer event) after the CSV is received (e.g., via FTP or Appian's File System utilities), then call a stored procedure via the ''Execute Stored Procedure'' smart service. The stored procedure can efficiently bulk-load the CSV (e.g., using SQL's BULK INSERT or equivalent), process the data, and update tables---all within the database's optimized environment. This ensures completion by 8:00 AM and aligns with Appian's recommendation to offload complex, large-scale data operations to the database layer, maintaining Appian as the orchestration layer.
D . Process what can be completed easily in a process model after each integration, and complete the most complex tasks using a set of stored procedures:
This hybrid approach splits the workload: simple tasks (e.g., validation) in a process model, and complex tasks (e.g., transformations) in stored procedures. While this leverages Appian's strengths (orchestration) and database efficiency, it adds unnecessary complexity. Managing two layers of processing increases maintenance overhead and risks partial failures (e.g., process model timeouts before stored procedures run). Appian's best practices favor a single, cohesive approach for bulk data integration, making this less efficient than a pure stored procedure solution (C).
Conclusion: Creating a set of stored procedures (C) is the best option. It leverages the database's native capabilities to handle the high volume and complexity of the CSV integration, ensuring fast, reliable processing between 1:00 AM and 8:00 AM. Appian orchestrates the trigger and integration (e.g., via a process model), while the stored procedure performs the heavy lifting---aligning with Appian's performance guidelines for large-scale data operations.
Appian Documentation: 'Execute Stored Procedure Smart Service' (Process Modeling > Smart Services).
Appian Lead Developer Certification: Data Integration Module (Handling Large Data Volumes).
Appian Best Practices: 'Performance Considerations for Data Integration' (Database vs. Process Model Processing).
Start a Discussions
You are the lead developer for an Appian project, in a backlog refinement meeting. You are presented with the following user story:
''As a restaurant customer, I need to be able to place my food order online to avoid waiting in line for takeout.''
Which two functional acceptance criteria would you consider 'good'?
Correct : A, D
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, defining ''good'' functional acceptance criteria for a user story requires ensuring they are specific, testable, and directly tied to the user's need (placing an online food order to avoid waiting in line). Good criteria focus on functionality, usability, and reliability, aligning with Appian's Agile and design best practices. Let's evaluate each option:
A . The user will click Save, and the order information will be saved in the ORDER table and have audit history:
This is a ''good'' criterion. It directly validates the core functionality of the user story---placing an order online. Saving order data in the ORDER table (likely via a process model or Data Store Entity) ensures persistence, and audit history (e.g., using Appian's audit logs or database triggers) tracks changes, supporting traceability and compliance. This is specific, testable (e.g., verify data in the table and logs), and essential for the user's goal, aligning with Appian's data management and user experience guidelines.
B . The user will receive an email notification when their order is completed:
While useful, this is a ''nice-to-have'' enhancement, not a core requirement of the user story. The story focuses on placing an order online to avoid waiting, not on completion notifications. Email notifications add value but aren't essential for validating the primary functionality. Appian's user story best practices prioritize criteria tied to the main user need, making this secondary and not ''good'' in this context.
C . The system must handle up to 500 unique orders per day:
This is a non-functional requirement (performance/scalability), not a functional acceptance criterion. It describes system capacity, not specific user behavior or functionality. While important for design, it's not directly testable for the user story's outcome (placing an order) and isn't tied to the user's experience. Appian's Agile methodologies separate functional and non-functional requirements, making this less relevant as a ''good'' criterion here.
D . The user cannot submit the form without filling out all required fields:
This is a ''good'' criterion. It ensures data integrity and usability by preventing incomplete orders, directly supporting the user's ability to place a valid online order. In Appian, this can be implemented using form validation (e.g., required attributes in SAIL interfaces or process model validations), making it specific, testable (e.g., verify form submission fails with missing fields), and critical for a reliable user experience. This aligns with Appian's UI design and user story validation standards.
Conclusion: The two ''good'' functional acceptance criteria are A (order saved with audit history) and D (required fields enforced). These directly validate the user story's functionality (placing a valid order online), are testable, and ensure a reliable, user-friendly experience---aligning with Appian's Agile and design best practices for user stories.
Appian Documentation: 'Writing Effective User Stories and Acceptance Criteria' (Functional Requirements).
Appian Lead Developer Certification: Agile Development Module (Acceptance Criteria Best Practices).
Appian Best Practices: 'Designing User Interfaces in Appian' (Form Validation and Data Persistence).
Start a Discussions